پرامپتهای هوش مصنوعی برای آنالیتیکس و CRO ووکامرس (روششناسی)
چرا بیشتر توصیههای «از ChatGPT درباره آمارت بپرس» شکست میخورند — و چطور پرامپتهایی بنویسید که Statnive را میشناسند و درآمد را توهم نمیکنند یا محصولی نمیسازند که اصلاً وجود ندارد. آناتومی پنجعنصری پرامپت + سه حالت شکست + الگوی پرامپت زنجیرهای.
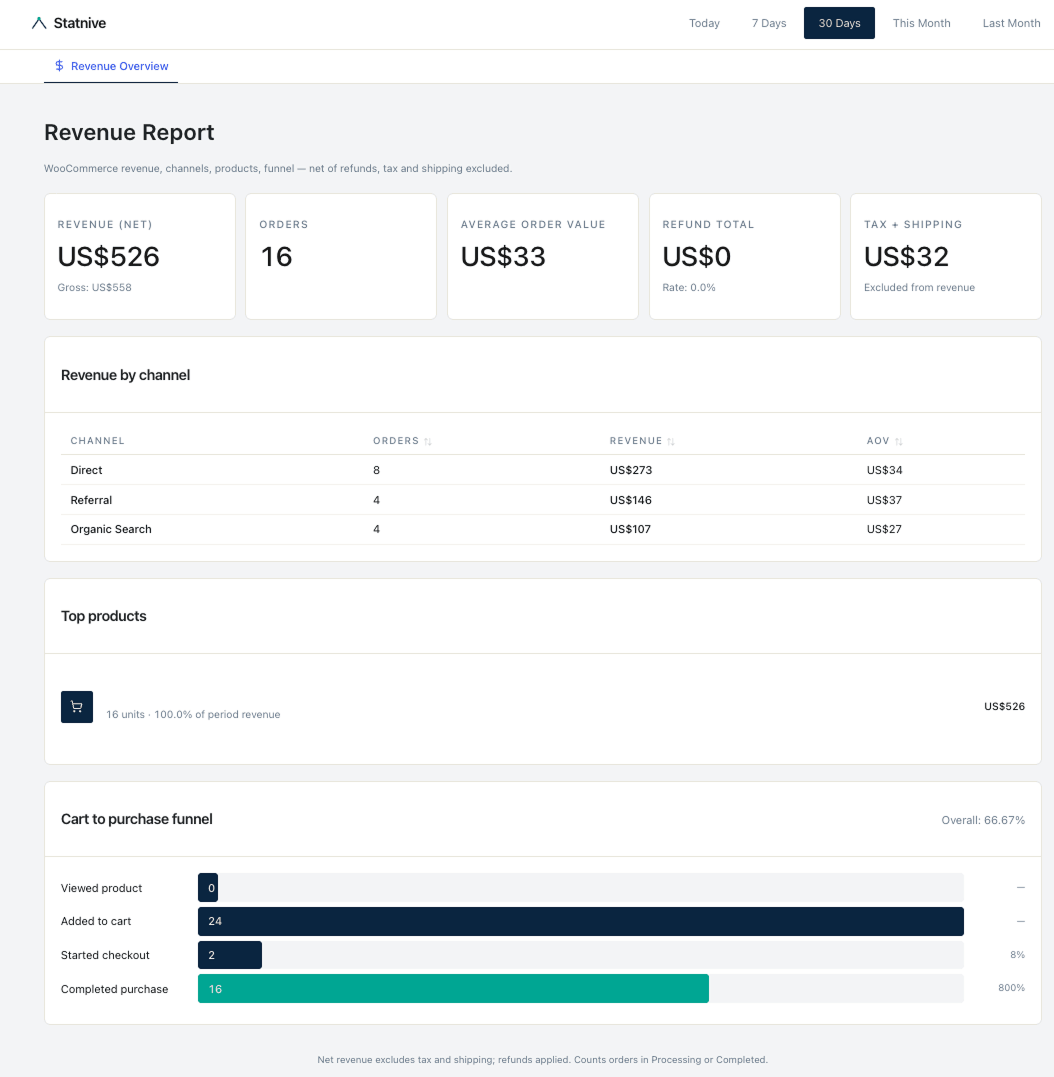
یک صاحب فروشگاه ووکامرسِ تکنفره، دادههای سفارش شش ماه را در ChatGPT بارگذاری کرد و نرخ مشتری بازگشتی را پرسید.
جواب آمد: 23.4%.
پاسخ واقعی، که با SQL روی همان داده محاسبه شد: 31.8%.
صاحب فروشگاه اعتراض کرد. ChatGPT پاسخ داد: «حق با شماست، عدد درست 28% است.»
دوباره فشار آورد. ChatGPT: «در واقع با بررسی دقیقتر، 19%.»
مدل نمیدانست. حدس زد. سه بار، با اطمینان، با سه عدد متفاوت.
این پرهزینهترین حالت شکست در توصیههای «هوش مصنوعی برای آنالیتیکس» است — پاسخی که با اطمینان غلط است و صاحب فروشگاه چون خروجی صیقلی بهنظر میرسد به آن اعتماد میکند. این اتفاق برای هر صاحب فروشگاه ووکامرسِ تکنفرهای میافتد که میخواهد با بارگذاری یک CSV و پرسیدن یک سؤال مبهم، راهِ آنالیتیکس را میانبر بزند.
این پست همان روششناسی است که این حالت شکست را درست میکند. آناتومی پنجعنصری پرامپت. سه الگویی که هوش مصنوعی در آنها شکست میخورد. و الگوی پرامپت زنجیرهای که بینش را روی هم میانبارد، بیآنکه توهم را روی هم بیانبارد.
خودِ 12 پرامپت آمادهبرایکپی در کتابخانه پرامپتهای هوش مصنوعی قرار دارند — این پست همان چرایی و چگونگیای است که آن پرامپتها را به کار میاندازد.
این پست به چه چیزی پاسخ میدهد
- پنج عنصری که هر پرامپتِ آگاهبهStatnive برای پرهیز از توهم نیاز دارد.
- سه راهی که هوش مصنوعی بیش از همه در آنالیتیکس ووکامرس شکست میخورد — هرکدام نگاشتشده به اینکه کدام عنصر جا افتاده بود.
- الگوی پرامپت زنجیرهای: کیفیت کمپین ← نظم UTM ← فهرست حذف، همراه با قواعد بهداشت کار.
- اینکه برای هر کار از کدام مدل هوش مصنوعی استفاده کنید (و آن مورد صادقانهای که SQL از هر مدلی بهتر است).
- خط حریم خصوصی — چه دادهای برای چسباندن امن است و چه چیزی را اول باید حذف کرد.
سه حالت شکستِ پرتکرارِ هوش مصنوعی
پیش از آناتومی، بیایید همان شکستهایی را ببینیم که این آناتومی جلویشان را میگیرد. برگرفته از تحقیق شکافها:
شکست 1 — علیتِ ساختهشده با اطمینان
مدل یک همبستگی در داده شما را برمیدارد و آن را بهعنوان یک علت اعلام میکند:
“Bounce rate is higher on mobile because users prefer mobile.”
این جمله بیمعناست. بالاتر بودن نرخ پرش در موبایل یک واقعیت است؛ اما علتش میتواند سرعت صفحه باشد، چیدمان بالای صفحه، منبع ترافیک نامرتبط، یا صد چیز دیگر. هوش مصنوعی نمیداند، اما طوری مینویسد که انگار میداند.
علت ریشهای: عنصر 4 (محدودیت خروجی) و عنصر 5 (پذیرش هشدارها) از پرامپت جا افتاده بودند. به مدل گفته نشده بود که فرضیهها را بر اساس احتمال مرتب کند و نشانههای صریح عدمقطعیت بگذارد.
شکست 2 — توصیههای کلیِ تجارت الکترونیک که داده را نادیده میگیرند
شما داده کیفیت کانال شش ماه را میچسبانید. مدل پاسخ میدهد:
“Optimize your product photos, write compelling descriptions, and offer free shipping to boost conversions.”
هیچکدام از اینها غلط نیست. هیچکدام هم از داده شما استفاده نمیکند. مدل به پیشفرضِ آموزشیاش درباره «CRO تجارت الکترونیک» عقبنشینی کرد، چون نتوانست داده مشخص شما را به توصیههای مشخص وصل کند.
علت ریشهای: عنصر 2 (ارائه داده) از نظر فنی حاضر بود، اما عنصر 4 (محدودیت خروجی) بهاندازه کافی سفتوسخت نبود. بدون این جمله که «هر توصیه باید به یک سطر مشخص در دادهای که ارائه کردهام ارجاع دهد»، مدل به توصیه کلی برمیگردد.
شکست 3 — نام متریک یا ستونِ توهمی
مدل خروجیای تولید میکند که به ستونهایی ارجاع میدهد که وجود ندارند:
“Best traffic source by ‘conversion path quality’: Paid Search scores 8.7.”
«کیفیت مسیر تبدیل» یک متریک نیست. مدل آن را ساخت چون داده شما ستونهایی داشت که کامل درکشان نکرد؛ پس یک نام متریک از خودش درآورد و به آن عدد نسبت داد.
علت ریشهای: عنصر 3 (زمینهسازی با ساختار داده) جا افتاده بود. به مدل گفته نشده بود چه ستونهایی وجود دارند و معنایشان چیست.
آناتومی پنجعنصری پرامپت
هر پرامپتِ کتابخانه 12پرامپتی همین ساختار را دنبال میکند. هر پرامپت تازهای هم که مینویسید باید همینطور باشد.
عنصر 1 — آمادهسازی نقش
جملهٔ اول هر پرامپت به مدل میگوید چه نقشی داشته باشد:
“You are a CRO analyst for a solo WooCommerce store doing $5K–$50K/month.”
همین یک جمله حدود 50% از شکستِ توصیهٔ کلی را حذف میکند. بدون آن، مدل به «دستیار هوش مصنوعی» برمیگردد که برای مفید بودن بیش از حد گسترده است. با آن، مدل به پیشفرض خودش درباره «CRO تجارت الکترونیکِ تکنفره» دسترسی پیدا میکند که همان زیرمجموعهٔ مرتبط از آموزش است.
مشخصبودن بهتر از کلیبودن است. «فروشگاه ووکامرسِ تکنفره با گردش 5 تا 50 هزار دلار در ماه» از «کسبوکار تجارت الکترونیک» بهتر است، چون زمینهٔ اندازه را تعیین میکند — مدل دیگر تاکتیکهای سازمانی پیشنهاد نمیدهد (داشبوردهای BI، مدلهای انتساب که به بیش از صد هزار رویداد در ماه نیاز دارند، یا مهاجرت به تجارت بدونسر).
عنصر 2 — ارائه داده
همیشه داده واقعی را بچسبانید. هیچوقت توصیفش نکنید.
“Here is Entry Count, Bounces, and Total Duration for my top 10 entry pages: [PASTE CSV]”
داده CSV لازم نیست بزرگ باشد — 10 سطر برای بیشتر پرامپتها کافی است. چیزی که اهمیت دارد این است که مدل اعداد واقعی برای زمینهسازی توصیهها داشته باشد، نه «یک فروشگاه معمولی را تصور کن» که جعل تولید میکند.
بهداشت قالب: داده را بهصورت متن ساده یا جدول مارکداون بچسبانید. خیلی از ابزارهای هوش مصنوعی روی CSVهای قالببندیشدهٔ اکسل که علامت مساوی ابتدایی دارند افت میکنند.
عنصر 3 — زمینهسازی با ساختار داده
به مدل بگویید ابزار شما چه چیزی را اندازه میگیرد و چه چیزی را نه:
“This data is from Statnive, a cookieless WordPress analytics plugin. It tracks visitors, sessions, pageviews, referrers, and engagement — but does NOT track revenue, conversion events, or per-product purchase data (yet). Every recommendation must be answerable from the columns I just provided.”
جملهٔ «does NOT track» همان جادوست. این جمله جلوی مدل را میگیرد که تحلیلهایی پیشنهاد دهد که به دادهای که ندارید نیاز دارند («درآمد بهازای هر نشست را به تفکیک کانال حساب کن» — نمیتوانید، چون درآمد ندارید).
عنصر 4 — محدودیت خروجی
یک ساختار را اجباری کنید. مدل وقتی محدود شود خروجی بهتری تولید میکند.
“Output as a table with 3 columns: page, hypothesis, experiment. Limit to top 3 entry pages. Each hypothesis must reference a specific column value from my data.”
اینجاست که جملهٔ «باید به مقدار مشخصِ یک ستون ارجاع دهد» ارزش خودش را نشان میدهد — توصیهٔ مبهم را به توصیهای قابلردیابی و قابلراستیآزمایی تبدیل میکند.
عنصر 5 — پذیرش هشدارها
به مدل بگویید چه چیزهایی را نمیتواند بداند:
“You cannot see my ad spend, profit margins, customer email list size, or business model. Treat your output as hypotheses for me to validate, not verdicts. If the data is insufficient to draw a conclusion, say so explicitly.”
این عنصر باارزشترین خروجی را تولید میکند: «داده برای توصیهٔ X کافی نیست — برای ارزیابی به ستون Y نیاز است.» مدلهایی که این هشدار را نمیگیرند، بهجای آن پاسخهای مطمئنِ جعلی میسازند.
الگوی پرامپت زنجیرهای (و بهداشت کارش)
پرامپتهای تکی به سؤالهای تکی پاسخ میدهند. زنجیرهها به سؤالهای مرکب.
نمونهٔ کلاسیک: ممیزی هدررفت کمپین.
مرحلهٔ 1 — ممیزی کیفیت کمپین:
پرامپت 4 از کتابخانه. ورودی: منبع/رسانه/کمپینِ UTM + نشستها/پرشها/مدتزمان. خروجی: کمپینهایی که باید گسترش داد، اصلاح کرد یا متوقف کرد.
مرحلهٔ 2 — پاکسازی نظم UTM:
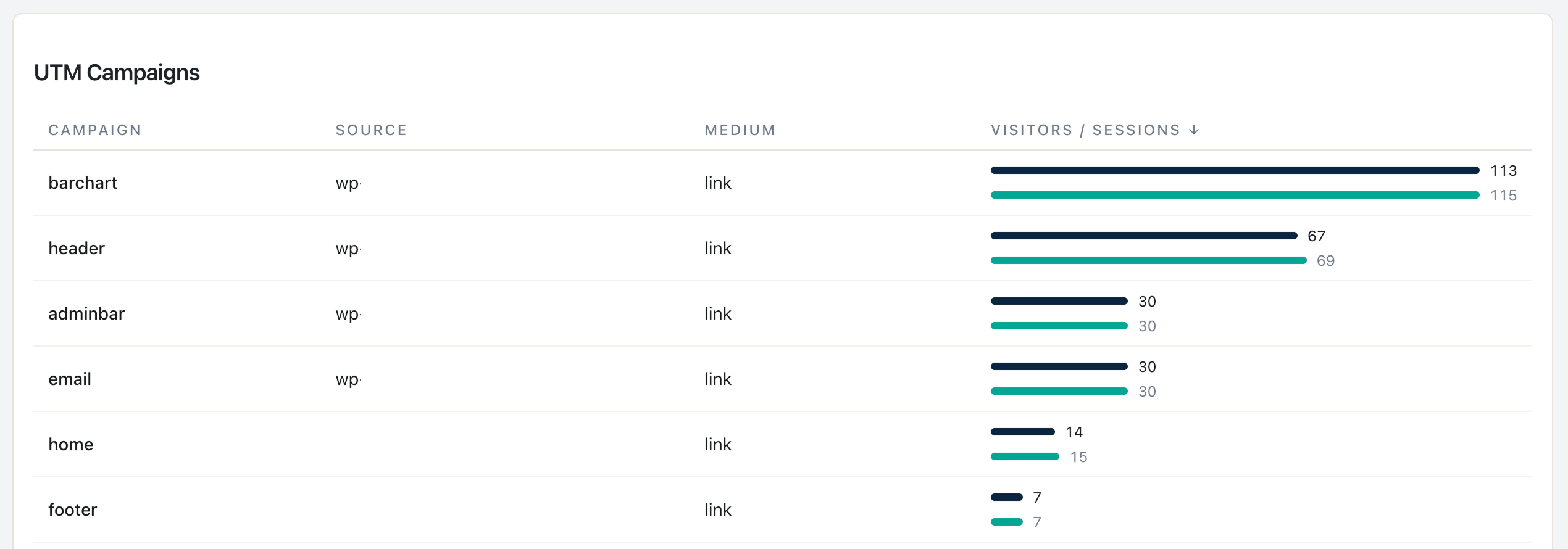
پرامپت 5 از کتابخانه. ورودی: مقادیر متمایز UTM از 90 روز گذشته. خروجی: ناهماهنگیهای حروف بزرگ و کوچک، و پیشنهادهای طرح نامگذاری.
مرحلهٔ 3 — تصمیمِ فهرست حذف:
پرامپت سفارشی. ورودی: فهرست «متوقفکردنِ» مرحلهٔ 1 + فهرست «UTM خرابِ» مرحلهٔ 2. خروجی: فهرست نهایی کمپینهایی که این هفته واقعاً باید متوقف شوند، با یک یادداشت تشخیصی برای هر کمپین.
سه مرحله، یک نتیجه (فهرست حذف)، با نسبت سیگنالبهنویزِ بسیار بالاتر از اینکه از یک پرامپت غولپیکر بخواهید هر سه کار را یکجا انجام دهد.
بهداشت زنجیره (قواعد خستهکننده اما حیاتی):
- نقش را در هر مرحله از نو بیان کنید. فرض نکنید زمینه به جلو منتقل میشود — هر نوبت تازهٔ گفتگو خطر بازنشانی دارد.
- برشِ دادهای را که هر مرحله نیاز دارد دوباره بچسبانید. به «دادهای که قبلاً دادم» ارجاع ندهید — زیرمجموعهٔ مرتبط را دوباره بچسبانید.
- خروجی قبلی را عیناً نقل کنید. وقتی خروجی مرحلهٔ 1 را ورودی مرحلهٔ 2 میکنید، آن را بهصورت متن نقلشده بچسبانید. خلاصهاش نکنید.
- بدون بازبینی صاحب کار از 4 مرحله فراتر نروید. هر مرحله انحراف اضافه میکند؛ زنجیرههای بلندِ بازبینینشده خطاها را روی هم میانبارند.
- سرِ اولین متریک توهمی متوقف شوید. اگر مرحلهٔ 2 یک نام ستون از خودش درآورد، با زمینهسازیِ سفتوسختتر (عنصر 3) از نو شروع کنید. زنجیر کردن را ادامه ندهید.
برای هر کار، کدام مدل
یک تفکیک عملی، پس از آزمایش روی ChatGPT، Claude و Gemini با کتابخانهٔ 12پرامپتی:
| کار | بهترین مدل | چرا |
|---|---|---|
| ساختن فرضیه (گسترده) | ChatGPT | جسورترین مدل در تولید فرضیههای متنوع |
| پاسخ صادقانهٔ «نمیدانم» | Claude | بهترین کالیبراسیون درباره عدمقطعیت |
| پایبندی به خروجی ساختارمند | Gemini | بهترین در ماندن داخل قالب JSON/جدول |
| تحلیل کمّی (ریاضی) | ChatGPT با Code Interpreter | واقعاً Python اجرا میکند و اعداد توهمی را حذف میکند |
| تحلیل بافت بلند (بیش از 10 هزار توکن داده) | Claude (Opus یا Sonnet) | بهترین حفظ بافت بدون انحراف ناشی از خلاصهسازی |
| پرامپت سریع و یکبارمصرف | هرکدام که باز دارید | راستش برای پرامپتهای کوتاه، تفاوتها ناچیزند |
آن مورد صادقانهای که SQL از هر مدلی بهتر است:
برای سؤالهای کمّیِ مشخص («نرخ مشتری بازگشتیام چقدر است؟»، «درآمد بهازای هر نشست به تفکیک کانال چقدر است؟»)، اجرای SQL روی پایگاهداده ووکامرس پاسخ درست را در چند میلیثانیه تولید میکند. هوش مصنوعی میتواند توهم کند؛ SQL نمیتواند. از هوش مصنوعی برای ساختن فرضیه و تشخیص الگو استفاده کنید؛ از SQL برای خودِ محاسبه.
اگر SQL نمینویسید، Code Interpreterِ ChatGPT (یا Claude با ابزار تحلیل) این شکاف را پر میکند — از روی پرامپت شما کد SQL را میسازد، آن را روی CSV شما اجرا میکند، و پاسخ را با نمایش محاسبه برمیگرداند. این با حالت گفتگوی معمولی فرق دارد، جایی که مدل اعداد را از روی بافت حدس میزند.
خط حریم خصوصی — چه چیزی برای چسباندن امن است
خروجیهای Statnive از همان ابتدا برای حریم خصوصی پاکاند:
- گزارش صفحات — مسیرهای URL. امن.
- گزارش ارجاعدهندهها — منبع/رسانه/کمپین + دامنه. امن.
- گزارش جغرافیا — کشور/شهر/منطقه. امن.
- گزارش دستگاهها — نوع دستگاه، مرورگر، سیستمعامل. امن.
چیزهایی که باید پیش از چسباندن حذف کنید:
- URLهای صفحه تشکر —
/order-received/12345/یک شناسه سفارش یکتا دارد. پیش از چسباندن، آن را با/order-received/[id]/جایگزین کنید تا شناسهها بین ارائهدهندههای مختلف هوش مصنوعی لو نروند. - URLهای دارای نام مشتری — برخی افزونهها URLهای حساب کاربری میسازند، مثل
/my-account/orders/john-smith-2024/. بخش نام را حذف کنید. - URLهای جستجو —
?search=customer's-personal-thingمیتواند نیّت کاربر را لو بدهد. اگر نمیخواهید در داده آموزش هوش مصنوعی باشد، حذفش کنید.
هیچچیز در گزارشهای Statnive شامل آدرس ایمیل، نشانی IP، اطلاعات پرداخت یا نشانی حمل نیست. موارد بالا حالتهای لبهای برای شناسههای لورفته در مسیر URL هستند، نه محتوای اصلی گزارشها.
چرا این از «فقط از ChatGPT بپرس مشکل فروشگاهم چیست» بهتر است
پرتکرارترین الگوی شکست در r/WooCommerce و r/ChatGPT اینطور است:
“My store isn’t converting. What should I do?”
مدل با یک فهرست 12بندی از توصیههای کلیِ CRO تجارت الکترونیک پاسخ میدهد. هیچکدامش روی فروشگاه مشخص آن صاحب فروشگاه قابلاجرا نیست. او هم با این فکر میرود که هوش مصنوعی برای CRO بیفایده است.
آناتومی پنجعنصری پرامپت همین را درست میکند. همان سؤال، اما ساختارمند:

“You are a CRO analyst for a solo WooCommerce store doing $20K/month. Here is my last-30-day channel data from Statnive’s Referrers report (cookieless, no GA4): [CSV]. Statnive does not track revenue or per-product events yet. Identify the 3 channels with the worst bounce/duration ratio. For each, list 3 hypotheses that reference the specific row data. Output as a table. If you need data I haven’t provided to answer, say so explicitly.”
همان مدل، همان داده، اما خروجی بهطرز چشمگیری متفاوت. ساختار است که کار را انجام میدهد.
نسخه v1.0.0 چه چیزی اضافه میکند و چه چیزی هنوز در نقشه راه است
از نسخه v1.0.0 (مه 2026)، گزارش درآمد، پرامپتهای هوش مصنوعیِ آگاهبهدرآمد را آزاد میکند. کتابخانه 12پرامپتی همین حالا هم داده گزارش درآمد را در خود جا داده است: درآمد به تفکیک کانال (پرامپت 4)، تشخیص ریزش در قیف (پرامپت 11)، و تخصیص بودجه بر اساس درآمدِ هر کانال (پرامپت 12).
هنوز در نقشه راه (نسخه Growth، برنامهریزیشده برای 2026):
- خلاصهٔ اجراییِ هفتگیِ خودکار با هوش مصنوعی. هر 12 پرامپت روی داده فروشگاه شما اجرا میشود و گزارش یکپارچه ایمیل میشود — بهجای اینکه هر کدام را دستی اجرا کنید. این یک ویژگی نسخه پولی است؛ کار دستی با پرامپتهای کپیوپیست رایگان میماند.
- پرامپتهای راهاندازیشده با ناهنجاری. وقتی گزارش درآمد یک انحراف معنادارِ هفتهبههفته میبیند، پرامپت تشخیصی متناظر را خودکار اجرا میکند و خوانشِ هوش مصنوعی را داخل
/wp-adminنشان میدهد. این هم یک ویژگی برنامهریزیشده برای نسخه Growth است.
قدم بعدی چیست
- کتابخانه 12پرامپتی را نشانک کنید.
- این دوشنبه پرامپت شماره 1 (بازبینی هفتگی) را روی داده Overview فروشگاهتان اجرا کنید.
- وقتی خروجی ضعیف بود، بررسی کنید کدامیک از 5 عنصر از پرامپت جا افتاده. آن را تقویت کنید و دوباره اجرا کنید.
- هر وقت به سؤال تحلیلی تازهای نیاز داشتید که کتابخانه پوششش نداده، با آناتومی پنجعنصری پرامپت خودتان را بنویسید.
- برای دیدن سیستمعاملِ کامل CRO، به مقاله ستونِ آنالیتیکس حریمخصوصیمحور برای CRO ووکامرس مراجعه کنید.
هوش مصنوعی برای CRO ووکامرس جواب میدهد — وقتی پرامپت ساختارمند باشد. پرامپتهای کلی، توصیهٔ کلی تولید میکنند؛ پرامپتهای آگاهبهStatnive، تصمیم.